





尽管只有30亿参数,Ferret-UI Lite却能匹敌甚至超越参数量高达24倍的模型!以下是详细内容。
Ferret系列的前世今生
早在2023年12月,由9位研究人员组成的团队发表了一篇名为《FERRET: Refer and Ground Anything Anywhere at Any Granularity》的论文,首次推出了一种多模态大语言模型(MLLM),它能理解自然语言对图像中特定区域的指代:
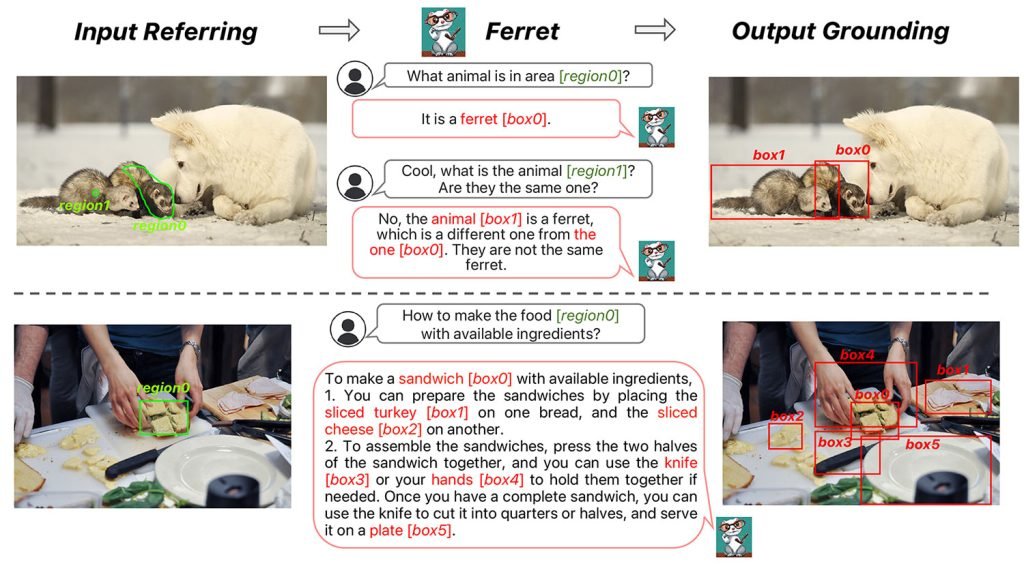
此后,苹果持续迭代Ferret家族,陆续发布了Ferretv2、Ferret-UI以及Ferret-UI 2等多个版本。
其中Ferret-UI系列专门针对通用多模态模型在用户界面(UI)理解上的短板进行了大幅强化。
原版Ferret-UI论文中写道:
尽管多模态大语言模型(MLLMs)近年来进步显著,但这些通用模型在理解和操作用户界面(UI)屏幕方面仍然表现欠佳。本文提出Ferret-UI,一款专为移动端UI屏幕深度理解而设计的新型MLLM,具备精准指代、定位和推理能力。考虑到UI屏幕通常长宽比更大、目标物体(如图标、文字)更小,我们在Ferret基础上加入“任意分辨率”支持,通过放大细节和增强视觉特征来大幅提升表现。
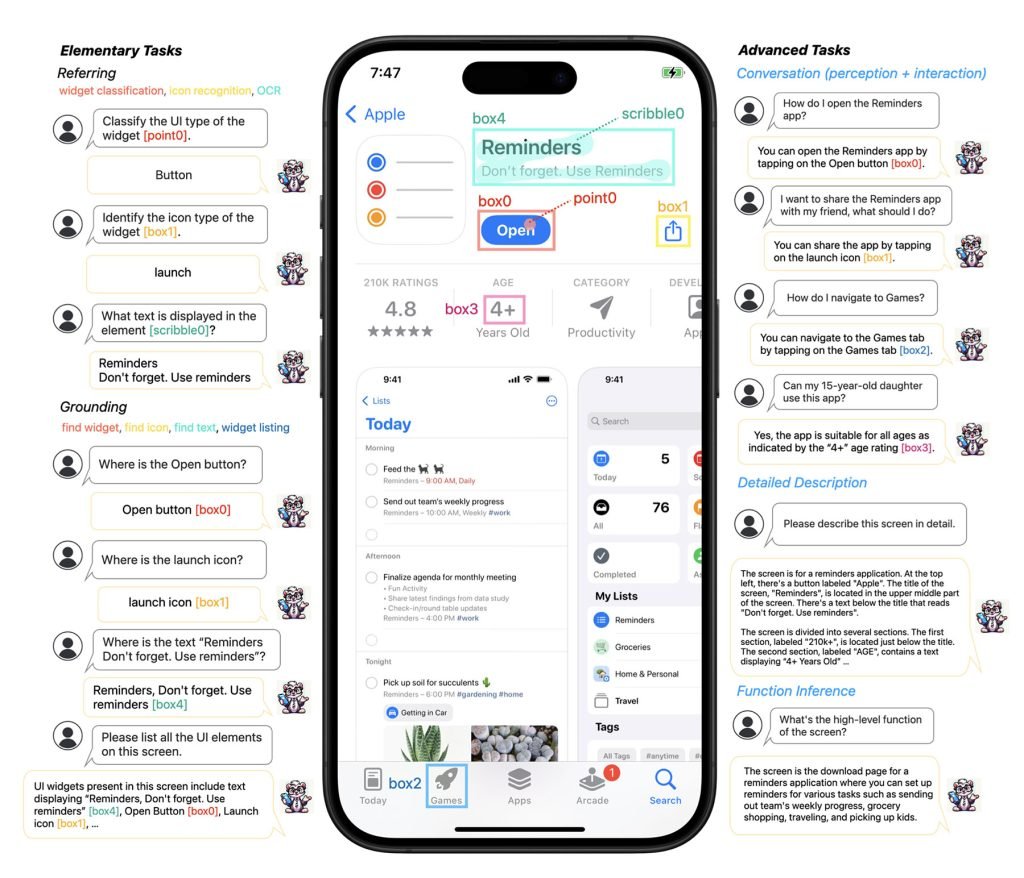
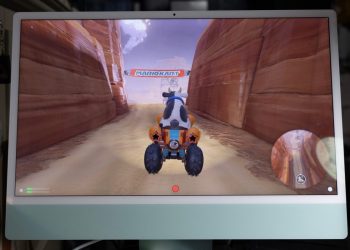
原版Ferret-UI研究展示了一个很有意思的应用:用户可以直接和模型对话,让它教你如何操作界面(如右图所示)。
几天前,苹果再次重磅更新Ferret-UI家族,发布了最新论文《Ferret-UI Lite: Lessons from Building Small On-Device GUI Agents》。
Ferret-UI基于130亿参数模型,主要聚焦移动UI理解和固定分辨率截图;Ferret-UI 2则进一步扩展到多平台支持和高分辨率感知。
而Ferret-UI Lite则走极致轻量化路线,专为设备端本地运行设计,却依然能与参数量大得多的GUI智能体正面硬刚。
Ferret-UI Lite:3亿参数的本地端黑马
论文作者指出,目前绝大多数GUI智能体方法都依赖“大底座模型”,因为“服务器端大模型强大的推理和规划能力,让这些智能体在各种GUI导航任务中表现出色”。
虽然多智能体系统和端到端GUI系统在低层定位、屏幕理解、多步规划、自我反思等环节已有不少进展,但它们体量过于庞大、算力需求极高,根本无法在设备端流畅运行。
于是研究团队打造了Ferret-UI Lite——一个仅有30亿参数的Ferret-UI变体,通过“小模型训练关键洞察”精心设计而成。
Ferret-UI Lite主要依靠以下几点实现突破:
- 来自多个GUI领域的真实+合成训练数据;
- 推理时动态裁剪+局部放大技术,精准聚焦关键区域;
- 监督微调 + 强化学习联合优化。
最终效果令人震惊:性能接近甚至反超参数量高达24倍的竞品GUI智能体。

整个架构细节非常精彩,但其中最值得关注的当属实时裁剪与局部放大技术。
模型先做初步预测 → 围绕预测区域裁剪 → 在裁剪后的小区域再次推理预测。这种迭代方式有效弥补了小模型处理超长图像token的先天劣势。

论文另一大亮点在于:Ferret-UI Lite几乎完全靠“自产自销”来生成训练数据。研究团队构建了一个多智能体系统,直接与真实GUI环境交互,大规模自动产生合成训练样本。
系统包含:课程任务生成器(逐步提出越来越难的目标)→ 规划智能体(拆解成步骤)→ 定位执行智能体(在屏幕上操作)→ 批评模型(评估结果好坏)。
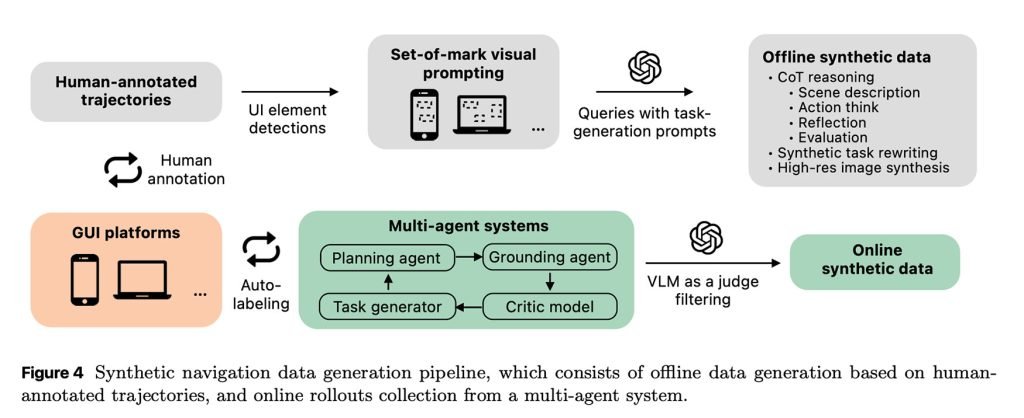
通过这一整套流水线,训练数据天然包含了真实世界交互中的各种模糊性(误操作、意外状态、纠错策略等),远比依赖人工标注的干净数据更贴近实际场景。
值得一提的是,Ferret-UI 和 Ferret-UI 2 主要使用iPhone截图等苹果生态进行评估,而Ferret-UI Lite则转向Android、Web和桌面GUI环境,使用AndroidWorld、OSWorld等公开基准进行训练与测试。
作者并未明确说明原因,但很可能与当前可复现、大规模GUI智能体测试床主要集中在这些平台有关。
测试结果显示,Ferret-UI Lite在短时、低复杂度任务上表现出色,但在长链、多步复杂交互上仍有明显差距——这也是设备端小模型的合理取舍。
但反过来,它实现了真正的本地化、私密化AI智能体:无需上传任何数据到云端,就能根据用户指令自主操作App界面,这一点非常酷炫。
想了解完整论文、详细基准对比和实验结果,请点击此处链接查看原文。