





一个已经修复的问题,让研究者成功绕过了苹果的限制,迫使设备上的大语言模型执行攻击者指定的操作。下面是他们具体的操作方式。
苹果已经加强了针对这种攻击的防护
今天在RSAC博客上发布的两篇博文(1、2)(via our)详细说明了研究者如何将两种攻击手法结合使用,通过提示注入让苹果的设备端模型执行攻击者控制的指令。
有趣的是,他们在并不完全清楚苹果本地模型如何处理部分输入和输出过滤流程的情况下,就成功完成了这次攻击。因为苹果出于安全考虑,并没有公开其模型内部机制的具体细节。
不过,研究者表示,他们对模型背后的工作原理已经有比较清晰的认识。
根据他们的分析,最可能的情况是:用户通过API调用向苹果的设备端模型发送提示后,首先会经过一个输入过滤器,检查请求是否包含不安全内容。
如果过滤器认为有问题,API就会失败;否则,请求会被转发给真正的设备端模型,模型生成回复后再交给输出过滤器检查。如果输出包含不安全内容,API同样会失败,否则就正常返回。
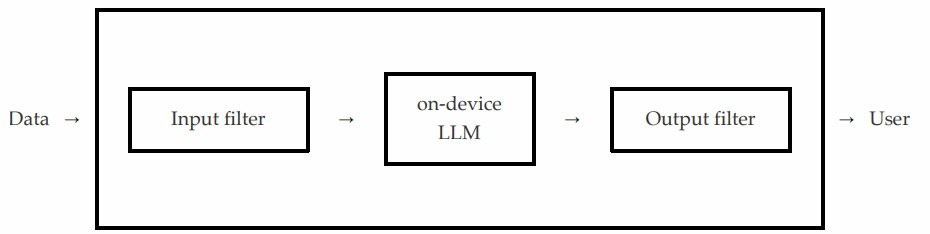
图片:烂苹果:RSAC成功实施苹果智能提示注入攻击的技术细节
他们具体是怎么做到的
基于这个流程,研究者发现可以通过组合两种攻击技术,让苹果的模型忽略基本的安全指令,同时骗过输入和输出过滤器,让有害内容顺利通过。
首先,他们把有害字符串反过来写,然后使用Unicode的RIGHT-TO-LEFT OVERRIDE字符,让它在用户屏幕上正常显示,但过滤器在检查原始输入和输出时,看到的仍然是反向的内容。
接着,研究者把这个反向的有害字符串嵌入到另一种名为Neural Exec的攻击方法中。这种方法本质上是一种复杂的方式,能够覆盖模型原有的指令,让模型执行攻击者想要的任何新指令。

图片:你口袋里的坏苹果?我们用提示注入劫持了苹果智能
结果,Unicode技巧成功绕过了输入和输出过滤器,而Neural Exec则真正让苹果的模型开始“听话”地执行有害操作。
为了评估攻击的有效性,我们准备了三个不同的内容池来构建合适的输入提示:
- 系统提示:一系列系统提示或任务(例如:“将提供的文本修改为符合美式英语拼写和标点习惯”)。
- 有害字符串:人工精心构造的、会被视为冒犯或有害的字符串(也就是我们希望模型被迫生成的输出)。
- 正常输入:从随机维基百科文章中摘取的段落,用来模拟非对抗性的、看起来无害的输入(比如在通过RAG等系统进行间接提示注入的场景中)。
评估过程中,我们从每个池中随机抽取一个元素,组合成完整的提示,构建带攻击载荷的payload(见下文),注入后通过操作系统调用苹果的设备端模型,测试攻击是否成功。
在他们的测试中,100个随机提示的成功率达到了76%。
他们于2025年10月将这个攻击报告给了苹果,苹果“随后对受影响的系统进行了加固,这些防护措施已随iOS 26.4和macOS 26.4版本推送”。
想阅读完整报告(其中包含攻击技术细节的链接),请点击这里。








