





麻省理工学院和Empirical Health的研究人员开展的一项新研究,利用300万人天的苹果手表数据,开发了一个能高精度预测医疗状况的基础模型。具体细节如下。
相关背景
早在Yann LeCun仍是Meta首席AI科学家时,他便提出了联合嵌入预测架构,其核心在于教导AI推断缺失数据的意义,而非数据本身。
换言之,在处理数据缺失时,该模型学习预测缺失部分所代表的含义,而非试图猜测并重建其精确值。
以图像为例,当部分区域被遮蔽而其他部分可见时,JEPA会将可见和遮蔽区域共同嵌入到一个共享空间,并让模型根据可见上下文推断遮蔽区域的表征,而非被隐藏的确切内容。
Meta在2023年发布I-JEPA模型时如此阐述:
去年,Meta首席AI科学家Yann LeCun提出了一种新架构,旨在克服当今最先进AI系统的关键局限。他的愿景是创造能够学习世界运作内部模型的机器,使其能更快学习、规划如何完成复杂任务,并轻松适应陌生情境。
自LeCun的原始JEPA研究发表以来,该架构已成为探索“世界模型”这一领域的基础,这标志着与LLM和GPT类系统专注令牌预测的路径分道扬镳。
事实上,LeCun近期已离开Meta,创办了一家完全专注于世界模型的公司,他认为这才是通向通用人工智能的真正道路。
那么,300万天的苹果手表数据?
是的,回到当前这项研究。论文《JETS:一种用于医疗行为数据的自监督联合嵌入时间序列基础模型》于数月前发表,近期被NeurIPS的一个研讨会接收。
该研究将JEPA的联合嵌入方法应用于不规则多元时间序列,例如长期可穿戴数据中心率、睡眠、活动等指标在时间上不一致或存在较大间隔的情况。
研究指出:
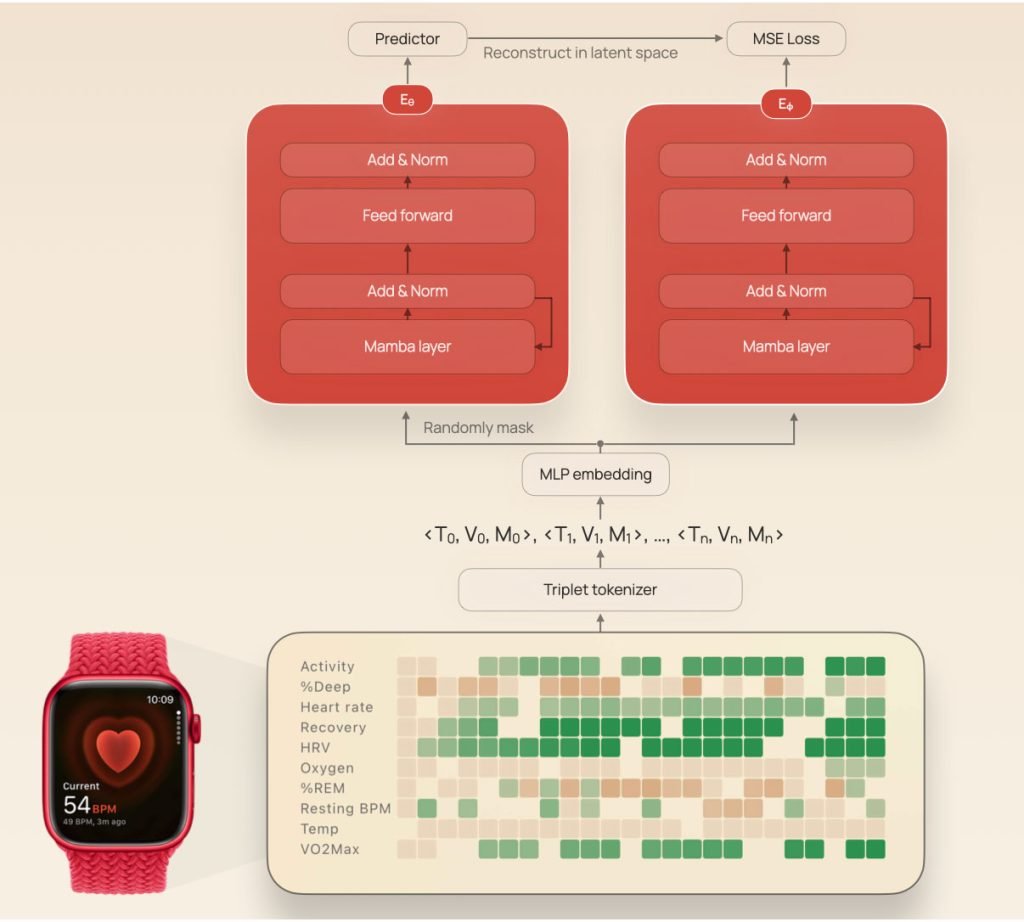
本研究使用的纵向数据集包含从16522名个体收集的可穿戴设备数据,总计约300万人天。对每位个体,以每日或更低分辨率记录了63个不同的时间序列指标。这些指标分为五个生理与行为领域:心血管健康、呼吸健康、睡眠、身体活动和一般统计。
值得注意的是,仅15%的参与者拥有用于评估的标记病史,这意味着85%的数据在传统的监督学习方法中将无法使用。相反,JETS首先通过自监督预训练从完整数据集中学习,然后在标记子集上进行微调。
为实现这一过程,他们将对应于日期、数值和指标类型的观测数据组成了三元组。
这使他们能够将每个观测转换为令牌,随后经过遮蔽处理、编码,并输入预测器以预测缺失块的嵌入。
完成上述步骤后,研究人员将JETS与其他基线模型进行比较,并使用AUROC和AUPRC这两个衡量AI区分正负案例能力的标准指标进行评估。
JETS在高血压检测上获得86.8%的AUROC,心房扑动为70.5%,慢性疲劳综合征为81%,病态窦房结综合征为86.8%。当然,它并非总是胜出,但其优势相当明显,如下图所示:
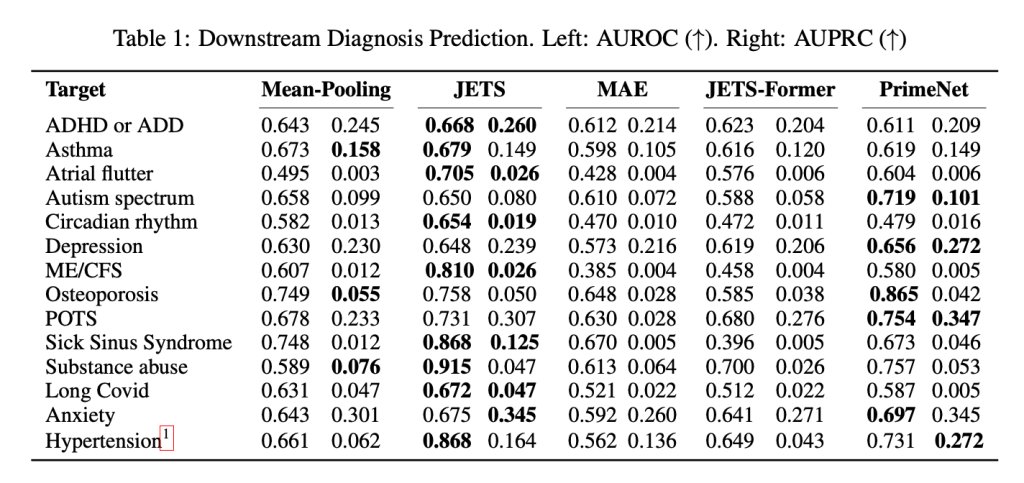
需要强调的是,AUROC和AUPRC并非严格的准确率指标。它们显示的是模型对可能病例进行排序或优先级区分的能力,而非预测正确的频率。
总而言之,这项研究提出了一种有趣的方法,能够最大化那些可能被归为不完整或不规则数据的洞察力与拯救生命的潜力。在某些情况下,健康指标仅被记录了0.4%的时间,而其他指标则在99%的每日读数中出现。
该研究也强化了一个观点:通过新颖的模型和训练技术来挖掘已被苹果手表等常规可穿戴设备收集的数据,具有巨大潜力,即使这些设备并非被100%持续佩戴。
您可以在此阅读完整研究。