





苹果的一组研究人员开发出了一个新框架,能以高得多的效率实现高分辨率3D场景渲染。下面就是这项最新研究的详细内容。
简单背景
在一篇题为《Less Gaussians, Texture More: 4K Feed-Forward Textured Splatting》的最新研究中,来自苹果和香港大学的研究人员提出了一种名为LGTM的新框架。
研究指出,随着分辨率不断提升,现有的前馈3D高斯溅射方法计算量会迅速增加,高分辨率场景的处理变得越来越不切实际。
简单来说,前馈3D高斯溅射就是让AI模型快速将一两张图片转换成可以从不同角度观看的3D场景。
其实我们之前报道过苹果开发的开源模型SPLAT,它采用的就是前馈3D高斯溅射技术,能从单张2D图片生成3D视图,效果非常出色:
前馈3D高斯溅射和传统的逐场景优化方法不同,后者是逐个场景一步步慢慢构建。虽然耗时更长,但结果往往更稳定。
因此,老方法虽然能在特定场景上花更多功夫,但前馈方法速度优势明显,只是以前的版本在高分辨率扩展上遇到了瓶颈。
LGTM
为了解决这个问题,研究人员提出了LGTM框架,它的核心思路是“将几何复杂度与渲染分辨率解耦”。
也就是说,它把场景的结构和视觉细节分开处理,系统可以保持简单的几何框架,同时通过纹理来丰富高分辨率的细节。
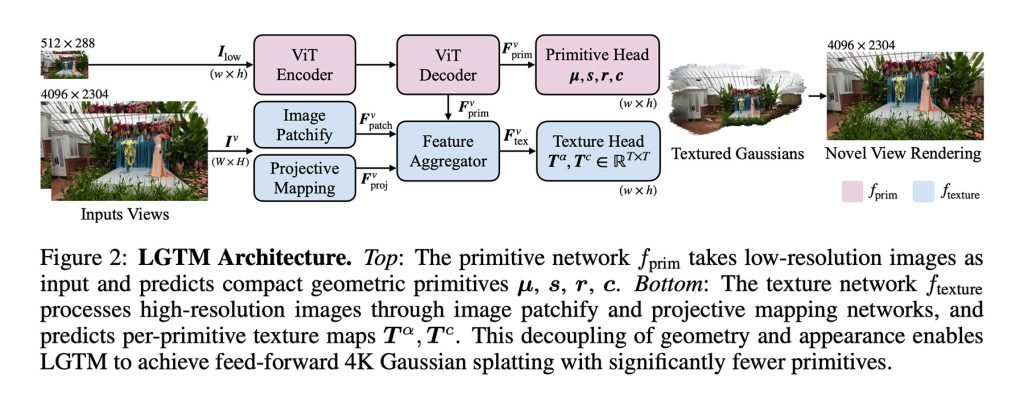
需要说明的是,LGTM本身不是一个独立的模型。它基于现有的前馈方法,通过在几何基础上叠加纹理预测来增强细节表现。
具体实现上,他们做了两步工作:
- 先让模型从低分辨率图像学习场景结构,然后用高分辨率真实图像作为标准来检验输出。这迫使模型学会生成即使在2K或4K下渲染也依然合理的几何体,避免出现空隙或瑕疵。
- 他们又引入了一个专注于外观的网络,专门处理高分辨率图像,为每个几何元素学习精细纹理,相当于在简单几何上叠加了丰富的视觉细节。
这样一来,框架就能让现有系统升级到生成精细4K场景,而不会像之前那样在高分辨率下出现计算量爆炸式增长的问题。
这对Apple Vision Pro等产品意味着什么
目前Apple Vision Pro的两个显示屏总像素约2300万,每只眼睛的像素量都超过了4K电视。
研究显示,前馈3D高斯溅射在这种分辨率下会遇到困难。虽然硬件显示能力足够,但快速准确生成场景成了计算上的瓶颈。
LGTM正好能帮助Apple Vision Pro缓解这个问题,从而在需要用到前馈3D高斯溅射的场景中,提供更流畅的性能和更清晰的画面。
实际体验上,这意味着用户可以享受更多细节丰富、沉浸感强的虚拟环境,或者更真实的透视效果,同时不会让设备处理器压力过大。
想要亲眼看看LGTM的效果,可以前往项目页面查看。它展示了NoPoSplat、DepthSplat和Flash3D等方法,在单视图和双视图输入下的表现,包括使用和不使用LGTM的对比。

翻看那些样本视频和图片,你会明显感觉到LGTM让最终结果细节丰富了很多,特别是纹理和文字部分,也更接近真实图像(样本里标为GT)。
翻看那些样本视频和图片,你会明显感觉到LGTM让最终结果细节丰富了很多,特别是纹理和文字部分,也更接近真实图像(样本里标为GT)。










