





苹果研究员发布了一项关于Manzano的研究,这是一款多模态模型,同时具备强大的视觉理解和文本到图像生成能力,并且大幅减少了当前方案在性能与质量之间的艰难取舍。下面来看详细内容。
直击最前沿难题的巧妙新方案
在题为《MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer》的研究中,近30位苹果研究员详细介绍了一种全新的统一架构,让单一多模态模型同时拥有出色的图像理解和文本到图像生成能力。
这非常重要,因为目前支持图像生成的统一多模态模型普遍面临艰难取舍:要么牺牲视觉理解能力来换取更好的自回归图像生成质量,要么优先保证理解能力而牺牲生成细节的保真度。换句话说,它们很难在两个任务上同时达到顶级表现。
研究人员解释了产生这种现象的根本原因:
造成这种差距的核心原因是视觉分词方式的根本冲突。自回归生成通常更喜欢离散的图像token,而视觉理解任务则通常受益于连续的嵌入表示。许多现有模型因此采用了双分词器策略:用语义编码器获取丰富的高层次连续特征,同时用独立的量化分词器(如VQ-VAE)来支持生成。但这导致语言模型必须同时处理两种完全不同的图像token表示——一种来自高层次语义空间,另一种来自低层次像素空间,从而造成严重的多任务冲突。虽然一些方法如Mixture-of-Transformers(MoT)通过为不同任务分配独立路径来缓解问题,但它们参数效率低下,并且与现代Mixture-of-Experts(MoE)架构往往不兼容。另一条技术路线则是直接冻结预训练的多模态大语言模型,再外接一个扩散解码器。虽然这种方式保留了理解能力,但完全解耦了生成过程,失去了两者之间潜在的相互增益,也限制了通过继续扩大多模态LLM来进一步提升生成质量的潜力。
简单来说,现有多模态架构很难同时做好理解和生成两件事,因为它们依赖于相互冲突的视觉表示,而同一个语言模型很难调和这种矛盾。
Manzano正是为了解决这个根本矛盾而生。它采用自回归大语言模型先预测图像在语义层面应该包含什么内容,然后将这些语义预测传递给扩散解码器(也就是我们之前介绍过的去噪过程),最终渲染出真实的像素图像,从而真正统一了理解与生成两大任务。
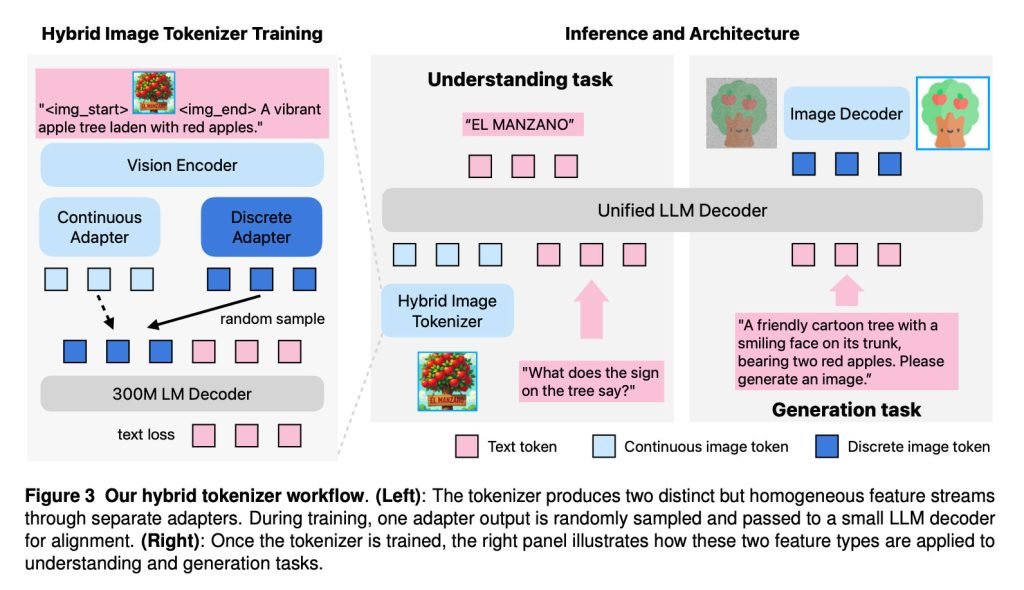
研究人员介绍,Manzano的架构主要由三大核心组件组成:
- 混合视觉分词器,同时输出连续型和离散型的视觉表示;
- 大语言模型解码器,接受文本token和/或连续图像嵌入,从联合词汇表中自回归预测下一个离散图像或文本token;
- 图像解码器,根据预测的图像token渲染出最终的像素图像
得益于这一创新设计,“Manzano在处理反常识、违反物理规律的极端提示(如‘鸟在大象下方飞翔’)时,表现可以媲美GPT-4o和Nano Banana”,研究人员表示。

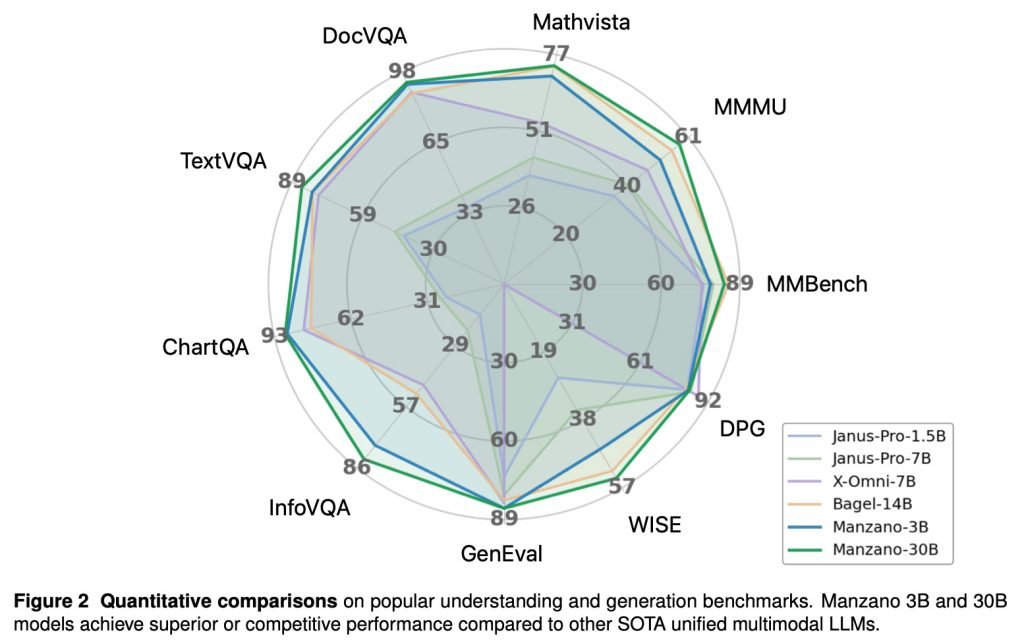
研究人员还指出,在多项权威基准测试中,“Manzano 3B和30B模型的表现优于或至少能与当前最顶级的统一多模态大语言模型相媲美。”
苹果团队对Manzano进行了从300M参数到30B参数的多种规模测试,清晰展示了随着模型规模扩大,统一多模态能力是如何稳步提升的:

下面是Manzano与谷歌Nano Banana、OpenAI GPT-4o等顶级模型的又一次直观对比:

此外,Manzano在图像编辑任务中也表现出色,包括指令引导编辑、风格迁移、局部重绘/扩展以及深度估计等功能。

想阅读包含混合分词器训练细节、扩散解码器设计、规模实验以及人工评估等完整技术内容的原论文,请点击此链接。
如果你对这类技术感兴趣,也推荐阅读我们之前关于UniGen的深度解析——那是苹果研究员近期公布的另一款极具潜力的图像模型。虽然这些模型目前都还没有在苹果设备上正式开放,但它们清楚地表明:苹果正在持续投入力量,致力于在Image Playground以及未来更多场景中实现更强大、更原生的图像生成能力。