





苹果持续深挖生成式AI如何革新应用开发流程,以下是他们最新的探索方向。
前情提要
几个月前,苹果研究团队发布了一项引人注目的研究:训练AI直接生成可用的UI代码。
那项研究关注的重点不是设计“美不美”,而是确保AI生成的代码能够成功编译,并且在功能和外观上大致符合用户的提示描述。
最终成果是开源的UICoder模型家族,你可以在这里了解更多详情。
全新研究重磅发布
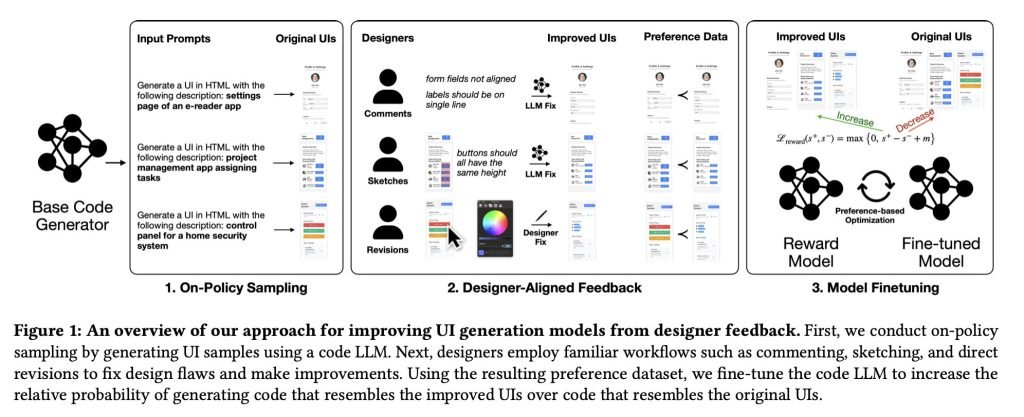
现在,UICoder核心团队再度出手,发布了新论文:《从设计师反馈中改进用户界面生成模型》。
论文指出,现有的基于人类反馈强化学习(RLHF)方法并不适合训练LLM可靠地生成高质量UI设计,因为它们“与设计师的实际工作流严重脱节,也忽略了设计师在评价和改进UI时所依赖的丰富设计理由”。
为此,他们提出了一条全新路径:请专业设计师直接对AI生成的UI进行点评、改进——使用文字评论、手绘草图,甚至直接上手修改界面,然后将这些“改前-改后”的变化转化为训练数据,用于微调模型。
通过这种方式,他们训练出了一个真正基于真实设计改进的奖励模型,有效教会UI生成器优先选择更符合现实世界设计判断的布局和组件。
实验规模与参与者
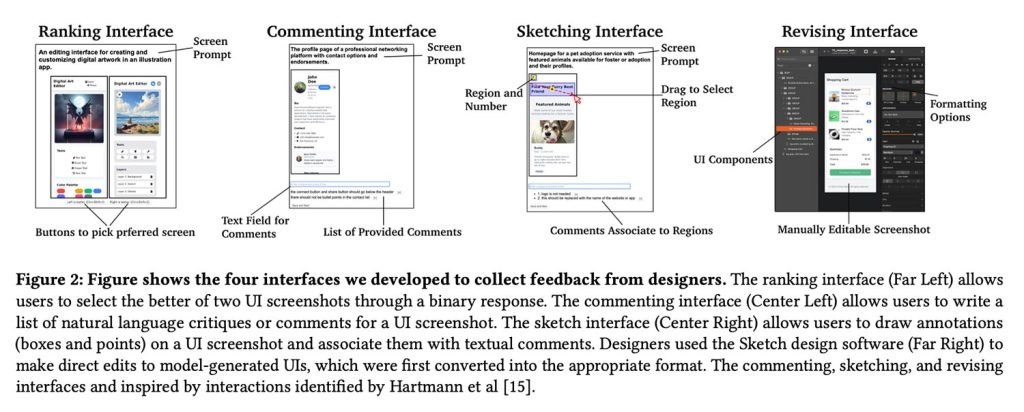
本次研究共邀请了21位专业设计师参与:
受邀设计师拥有从2年到30年以上的不同从业经验,覆盖UI/UX设计、产品设计、服务设计等多个领域。他们进行设计评审(正式或非正式)的频率也差异很大,从数月一次到每周多次不等。
研究团队共收集到1,460条设计师标注数据,并将其转化为成对的UI“偏好”样本:一边是原始模型生成的界面,另一边是设计师改进后的版本。
这些数据随后被用于训练奖励模型,再驱动UI生成器的微调:
奖励模型同时接收 i) 渲染后的UI截图 和 ii) 自然语言的目标描述。这两项输入经过模型处理后输出一个数值分数(reward),分数越高代表视觉设计质量越好。为了给HTML代码打分,我们使用第4.1节描述的自动化渲染流水线,通过浏览器自动化工具将代码渲染成截图后再评估。
在生成模型方面,苹果主要以Qwen2.5-Coder作为UI生成的基础模型,随后将同一套“设计师训练的奖励模型”应用到更小、更新版本的Qwen系列上,验证该方法在不同模型规模和版本上的泛化能力。
有趣的是,正如论文作者自己指出,整个框架在外形上与传统RLHF流程非常相似。但关键区别在于:学习信号来源于设计师最自然的工作方式(评论、草图、手动修订),而不是简单的点赞/点踩或排序数据。
惊人成果
那么,真的有效吗?研究者的答案是肯定的——但也有重要 caveat。
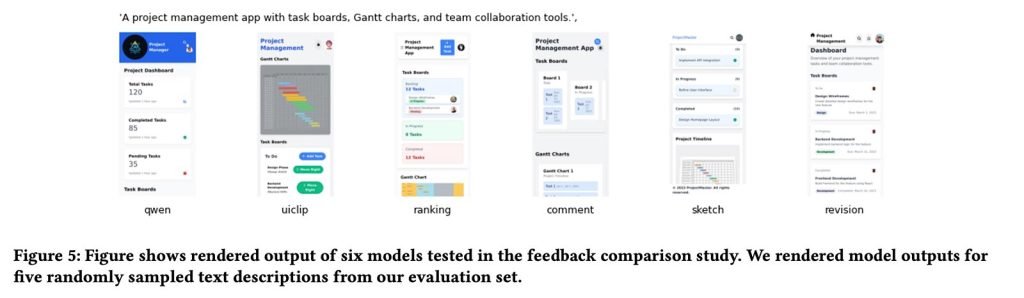
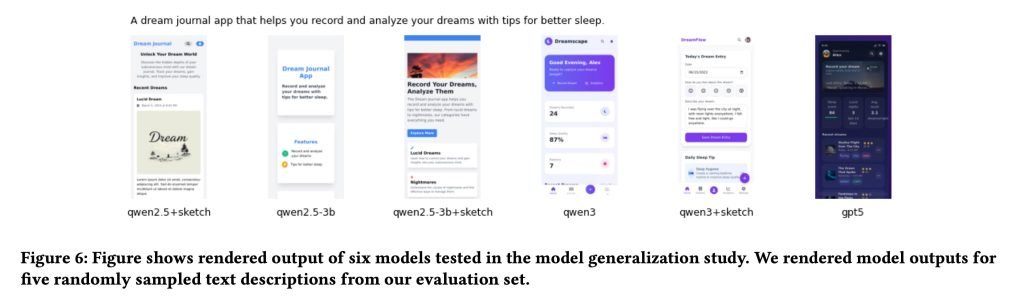
总体来看,使用“设计师原生反馈”(尤其是草图和直接修改)训练出的模型,生成的UI设计质量明显高于基础模型,也大幅超越仅使用传统排序或打分数据训练的版本。
最强模型(基于草图反馈微调的Qwen3-Coder)甚至超过了GPT-5。更令人震惊的是,这一结果仅依赖设计师提供的181条草图标注就实现了。
实验结果显示,基于草图的奖励模型微调在所有测试基线上一致带来UI生成能力的显著提升,展现出良好的泛化性。我们还证明:少量高质量专家反馈,就能让小型模型在UI生成任务上超越体量更大的闭源大模型。
但研究也坦承一个核心难题:什么是“好”的界面,始终带有很强的主观性:
我们工作以及其他人机交互问题的重大挑战在于处理设计的主观性和多解性。这两种现象都会导致反馈响应的高方差,给广泛使用的排序反馈机制带来很大困难。
实验中,当研究团队独立评估设计师排过序的相同UI对时,与设计师的判断仅有一致率49.2%——几乎就是抛硬币。
反过来,当设计师通过画草图或直接编辑来表达改进意图时,研究团队的认同率大幅提高:草图方式为63.6%,直接编辑高达76.1%。
换句话说:当设计师能具体展示“要改成什么样”,而不是仅仅在两个选项中选一个时,大家对“更好”的定义就更容易达成一致。
想深入了解这项研究的技术细节、训练材料和更多界面示例,可点击此处查看原文。










