





苹果联合特拉维夫大学研究团队找到了一种革命性方法:在不牺牲语音清晰度的情况下,大幅加速AI文本转语音生成。下面是他们到底怎么做到的。
颠覆性的高速语音生成新思路
在一篇题为《Principled Coarse-Grained Acceptance for Speculative Decoding in Speech》的全新论文中,苹果研究人员展示了一种极具创意的文本转语音生成方式。
目前文本转语音技术路线众多,研究团队重点关注的是自回归(autoregressive)文本到语音模型,这类模型一次只生成一个语音token。
如果你了解过如今的大型语言模型工作原理,就会很熟悉自回归模型:它根据前面所有token来预测下一个token。
自回归语音生成原理基本一致,只是这里的token代表的是音频片段,而不是单词或字符。
虽然这种方式生成语音已经相当高效,但苹果研究人员指出,它仍然存在严重的处理瓶颈:
然而,对于生成声学token的语音大模型,精确的token匹配过于苛刻:许多离散token在听觉或语义上是可以互相替换的,这导致接受率大幅降低,严重限制了加速效果。
换句话说,自回归语音模型过于“死板”,哪怕预测结果听起来几乎一样,只要token序号对不上就会直接拒绝,导致整体速度严重受限。
重磅登场:Principled Coarse-Graining(PCG)原理性粗粒度接受
简单来说,苹果的核心洞察是:很多不同的token其实能发出几乎一模一样的声音。
基于这个发现,苹果把听起来相似的语音token聚类分组,打造出一种更加宽松、灵活的验证机制。
形象点说:不再把每个细微的声音差别都当成完全不同的东西,而是允许模型接受属于同一个“听感相似组”的任何token。
实际上,PCG框架由两个模型协同工作:一个较小的快速提案模型负责迅速猜出语音token,另一个更大的“裁判”模型则负责检查这些token是否属于正确的声学相似分组,只有通过才正式接受。

这一框架成功将推测解码(Speculative Decoding)思想适配到生成声学token的语音大模型上,在保证语音可懂度的前提下大幅提升生成速度。
实验结果显示:PCG将语音生成速度提升约40%,而传统推测解码方法用在语音模型上几乎没有任何加速效果。
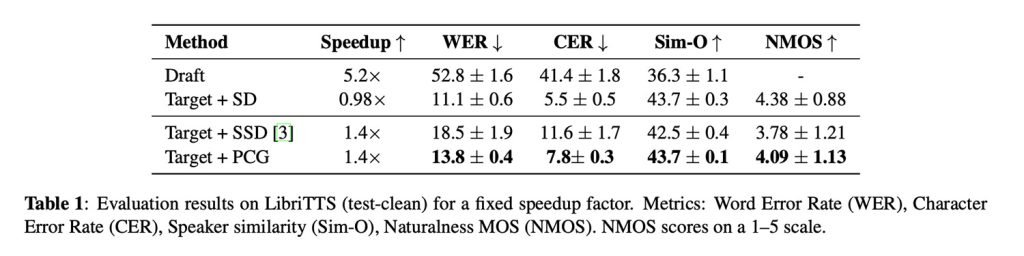
与此同时,PCG在保持极低词错率(WER)方面也大幅优于其他追求速度的方法,同时保留了极高的说话人相似度,最终获得4.09的自然度评分(人类1-5分标准评测)。
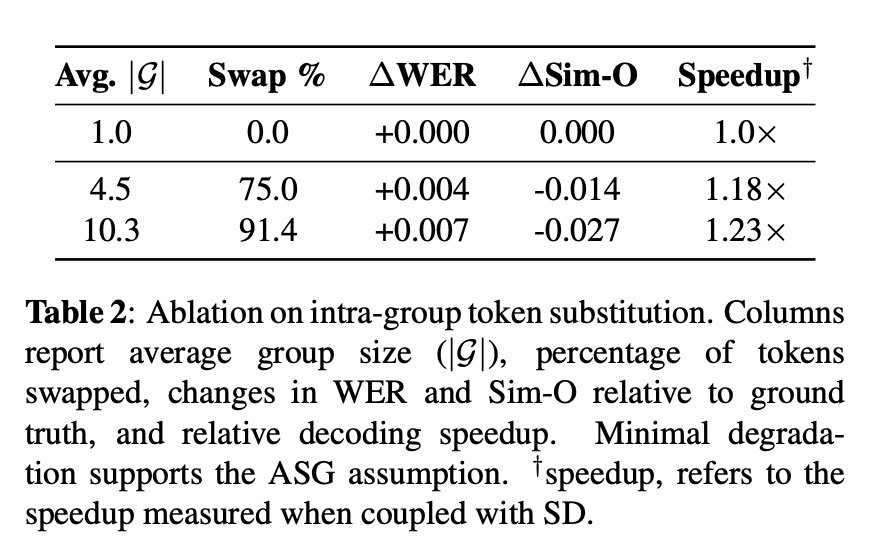
在一项极限替换测试(组内token替换消融实验)中,研究人员将91.4%的语音token替换为同组内其他备选token,音频质量依然稳如老狗:词错率仅上升+0.007,说话人相似度仅下降-0.027。
PCG真正落地后能带来什么?
虽然论文没有直接讨论对苹果产品和生态的具体影响,但这种技术非常适合未来需要同时兼顾速度、质量和功耗的语音功能。
最关键的一点:PCG是纯解码阶段的改进,完全不需要重新训练目标模型。也就是说,它可以直接应用到已经训练好的语音模型上,无需改动模型结构或重新训练。
此外,PCG的额外资源占用极低(仅需约37MB内存存储声学相似分组),完全适合在内存受限的设备上部署。
想了解PCG更详细的技术细节、数据集信息以及评估方法等完整内容,请点击此处查看原文。