





全新模型VSSFlow采用创新架构,仅用一套统一系统即可生成音效和语音,性能达到业界顶尖水平。下面来看看(并听听)一些演示效果。
问题所在
目前,大多数视频转声音模型(即从无声视频生成声音的模型)在生成语音方面表现平平。同样,大多数文本转语音模型由于设计目的不同,也无法很好地生成非语音音效。
此外,以往试图统一这两项任务的尝试往往基于一个假设:联合训练会降低性能,因此通常采用分阶段分别训练语音和音效的方式,这增加了整个流程的复杂性。
在这种背景下,三位苹果研究员联合中国人民大学的六位研究员,开发出VSSFlow——一款全新AI模型,能够在单一系统中从无声视频同时生成音效和语音。
更令人惊喜的是,他们设计的架构让语音训练能提升音效训练,反之亦然,二者非但不互相干扰,反而相辅相成。
解决方案
简单来说,VSSFlow融合了多项生成式AI技术,包括将转录文本转为音素token序列,并采用flow-matching从噪声中重建声音(我们此前报道过该技术),本质上是训练模型高效地从随机噪声起步,最终得到目标信号。
这一切都被嵌入到一个10层架构中,直接将视频和转录信号融合进音频生成过程,让模型能在单一系统中同时处理音效和语音。
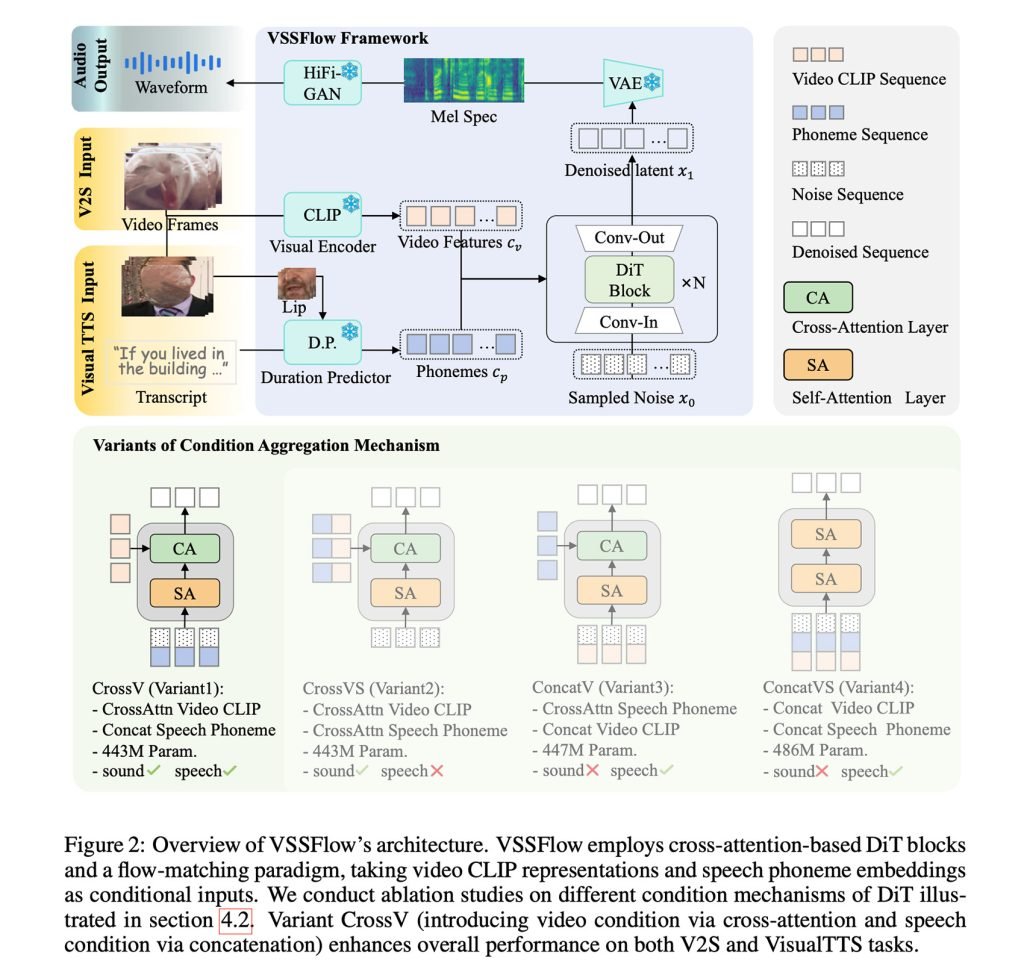
更有趣的是,研究人员发现,同时在语音和音效上联合训练不仅没有导致两者互相竞争或性能下降,反而让两项任务都得到了提升。
为了训练VSSFlow,研究团队向模型输入了混合数据:无声视频配环境音(V2S)、无声说话视频配转录文本(VisualTTS),以及文本转语音数据(TTS),让模型在端到端的单一训练过程中同时学习音效和口语对话。
值得注意的是,初始训练出的VSSFlow无法自动在单一输出中同时生成背景音效和对话语音。
为此,他们在已训练模型基础上,使用大量合成样本进行微调,这些样本中语音和环境音已被混合在一起,让模型学会同时输出两者的声音效果。
VSSFlow实战应用
要从无声视频生成音效和语音,模型从随机噪声开始,以每秒10帧的速度采样视频视觉线索来塑造环境音。同时,提供的对话转录文本则为生成的语音提供精确指导。
在与专为音效或专为语音设计的任务特定模型对比测试中,VSSFlow在两项任务上均展现出竞争力,尽管只用一套统一系统,却在多项关键指标上领先。
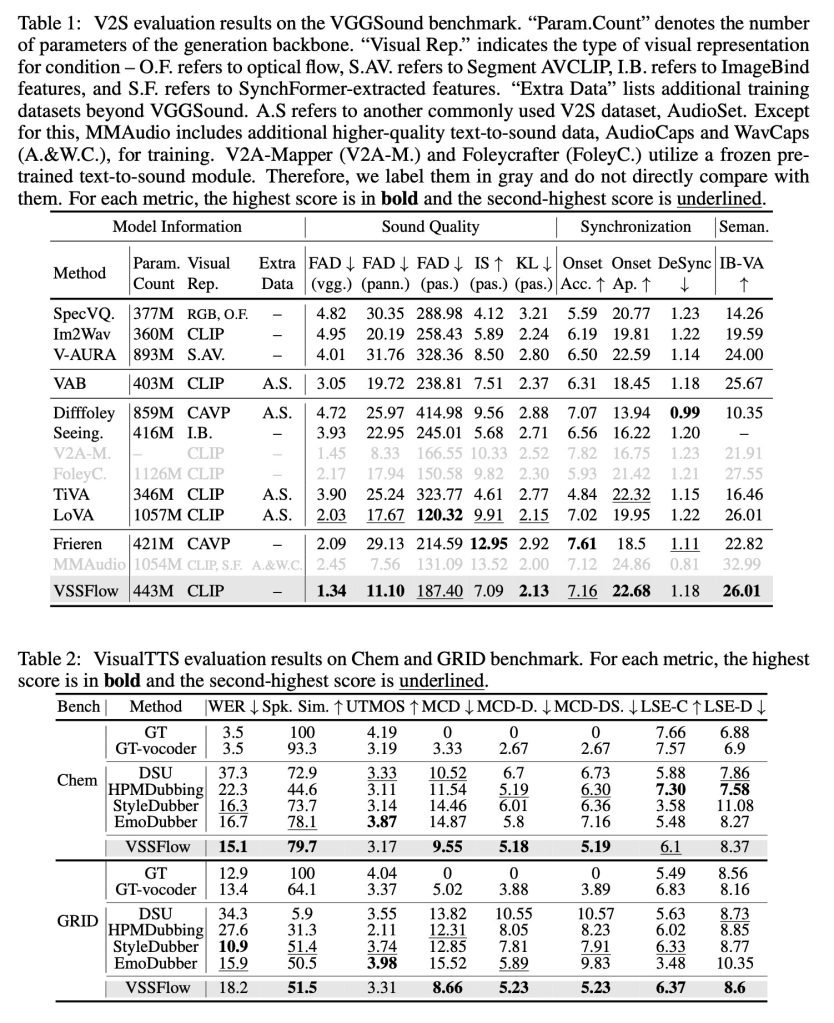
研究人员发布了多个音效、语音以及联合生成(基于Veo3视频)的演示结果,并与多种对比模型进行了比较。你可以先看看下面的部分结果,但建议前往演示页面查看全部内容。
更酷的是:研究团队已在GitHub上开源了VSSFlow的代码,并正在努力开源模型权重。此外,他们还在准备提供在线推理演示。
关于后续方向,研究人员表示:
本工作提出了一种统一的flow模型,将视频转声音(V2S)和视觉文本转语音(VisualTTS)任务整合在一起,为视频条件下的声音与语音生成建立了全新范式。我们的框架展示了一种高效的条件聚合机制,用于将语音和视频条件融入DiT架构。此外,通过分析我们揭示了声音-语音联合学习带来的相互促进效应,凸显了统一生成模型的价值。未来研究仍有多个值得深入探索的方向。首先,高品质视频-语音-声音数据的稀缺限制了统一生成模型的发展。此外,开发更好的声音与语音表示方法,在保持紧凑维度的同时保留语音细节,是未来的一项关键挑战。
想了解更多详情,请查看这项名为《VSSFlow: Unifying Video-conditioned Sound and Speech Generation via Joint Learning》的研究,点击此处链接。









