




苹果的研究团队开发了一款AI模型,只需要一张图片,就能重建出3D物体,而且从不同角度看的时候,反射、高光这些光影效果都能保持一致。下面是具体情况。
先简单聊聊背景
虽然机器学习里的“潜在空间”这个概念不算新鲜,但近几年随着基于Transformer的AI模型爆发,再加上最近的世界模型火起来,它变得比以往任何时候都更受关注。
简单来说(稍微牺牲一点严谨度,好让大家更容易懂),所谓“潜在空间”或者“嵌入空间”,其实就是把信息做两件事:
- 把各种信息浓缩成数字表示,代表它们的核心概念;
- 把这些数字放到一个多维空间里,这样就能算出它们在各个维度上的距离。
如果还是觉得有点抽象,可以想想那个经典例子:把“king”这个词的数学表示减去“man”的表示,再加上“woman”的表示,结果就会落到“queen”这个词所在的大致区域。
实际用起来,把信息存成潜在空间的数学表示,能让计算距离和预测生成内容的概率变得更快、更省算力。
这里有个短视频用另一种比喻解释潜在空间,大家可以看看:
上面例子主要是讲文本怎么存进潜在空间,但这个思路其实能用在很多其他类型的数据上。这就引到了苹果的这项研究。
LiTo:表面光场分词化
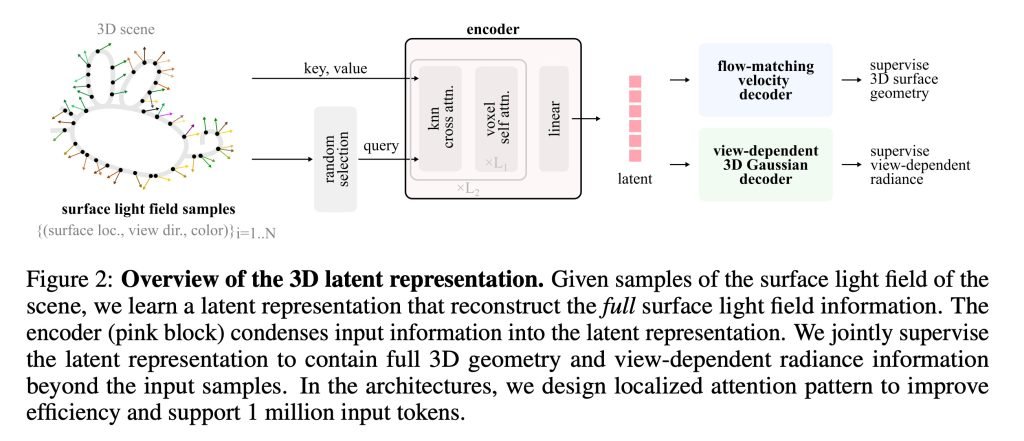
苹果最新这项研究叫《LiTo: Surface Light Field Tokenization》,研究人员提出了一种3D潜在表示方法,“同时建模物体的几何形状和与视角相关的外观”。
换句话说,他们找到了一种方式,在潜在空间里不光记录怎么重建3D物体,还记录光线跟物体交互后,从不同角度看过去应该是什么样子。
他们自己是这么描述的:
之前大多数工作要么专注重建3D几何,要么只预测与视角无关的漫反射外观,因此很难捕捉到真实的视角相关效果。我们这个方法利用了RGB-D图像其实就是表面光场的采样点。通过把表面光场的随机子样本编码成一组紧凑的潜在向量,我们的模型学会在同一个3D潜在空间里同时表示几何和外观。这种表示能很好地重现镜面高光、菲涅尔反射等视角相关的复杂光照效果。
更厉害的是,他们把模型训练到只需要单张图片就能做到这些,而不是像传统方法那样需要多角度照片才能重建3D。
虽然整个技术细节很复杂,论文里写得很细,但核心思路其实挺直白,只要搞懂潜在空间怎么回事就明白了:
- 先用编码器把物体信息压缩成潜在空间里一个很紧凑的表示。它不会记住每个细节,而是学会用简洁的数学描述物体的形状和表面怎么跟光互动。
- 然后解码器反过来操作,从这个压缩表示里重建出完整的3D物体,包括不同视角下反射、高光这些光影应该长什么样。
怎么训练LiTo
训练的时候,研究人员选了几千个物体,每个物体渲染了150个不同视角、3种光照条件。
然后系统并没有把所有数据一股脑喂给模型,而是每次随机挑一小部分样本,把它们压缩成潜在表示。
解码器就从这一小部分数据里学着重建完整的物体,以及不同角度和光照下的外观。
训练过程中,模型逐渐学会了既抓住物体的几何结构,又记住外观怎么随着视角变化。
之后他们又单独训练了一个模型,专门负责看单张图片就能预测出对应的潜在表示。接着解码器就能根据这个表示重建出完整的3D物体,包括视角改变时光影的相应变化。
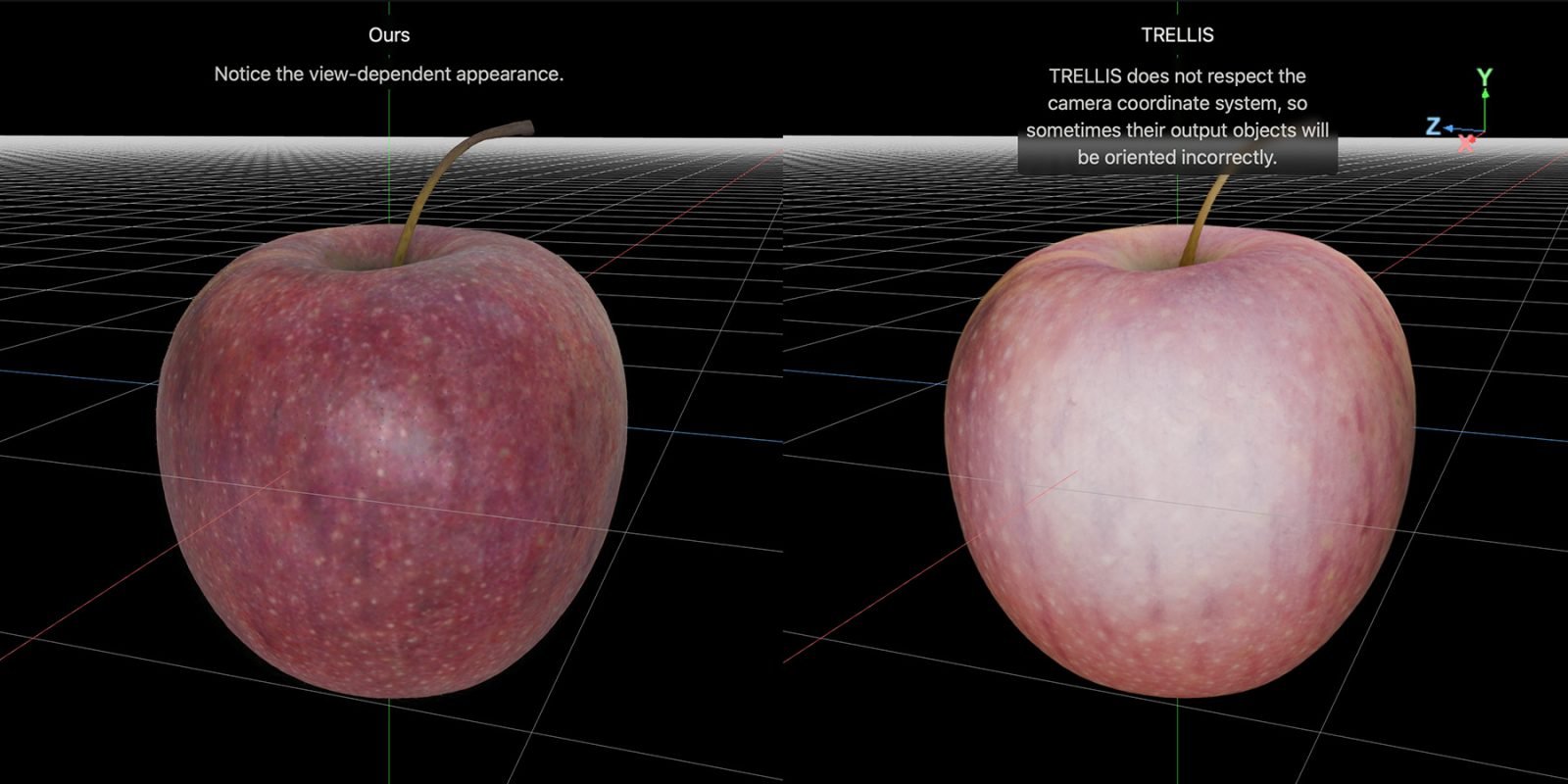
下面是苹果项目页面上放的LiTo跟另一个叫TRELLIS的模型的重建对比:
建议去项目页面看看,那里有LiTo和TRELLIS的并排互动对比,跟这篇文章的首图是一样的。
想看完整论文的话,可以点这个链接。










