





苹果的研究人员开发了一种新的AI训练方法,用来生成图像描述,不仅描述得更准确、更细致,而且模型规模要小得多。下面是具体情况。
这个新模型或许能让未来多模态AI的训练提速
在一项名为《RubiCap:基于评判标准的强化学习用于密集图像描述》的最新研究中,苹果的研究团队和威斯康星大学麦迪逊分校合作,提出了一种新的密集图像描述框架,在多个基准测试上都取得了目前最好的成绩。
密集图像描述的任务,是针对图像里每个区域生成详细的文字说明,而不是只给出一句整体概括。
简单说,它会找出图像中的多个物体和区域,然后用很细腻的语言分别描述它们,这样对整个场景的理解就会丰富得多,比单一的总体描述强很多。
下面是斯坦福大学早期密集描述论文《DenseCap》里的一些例子:

密集图像描述可以应用在很多地方,比如训练视觉-语言模型和文生图模型。如果用在面向用户的功能上,还能提升图像搜索的效果,甚至帮助无障碍工具做得更好。
研究人员指出,目前用AI训练密集图像描述模型的方法,存在不少明显不足:
密集图像描述对于视觉-语言预训练中的跨模态对齐以及文生图生成非常关键,但要大规模获取专家级标注,成本高得离谱。虽然用强大的视觉-语言模型(VLM)生成合成描述是个可行的替代方案,但监督蒸馏往往导致输出多样性不足,泛化能力也比较弱。强化学习(RL)理论上能解决这些问题,可它以前的成功主要集中在那些能用确定性检查器验证的领域,而开放式的图像描述并没有这种便利条件。
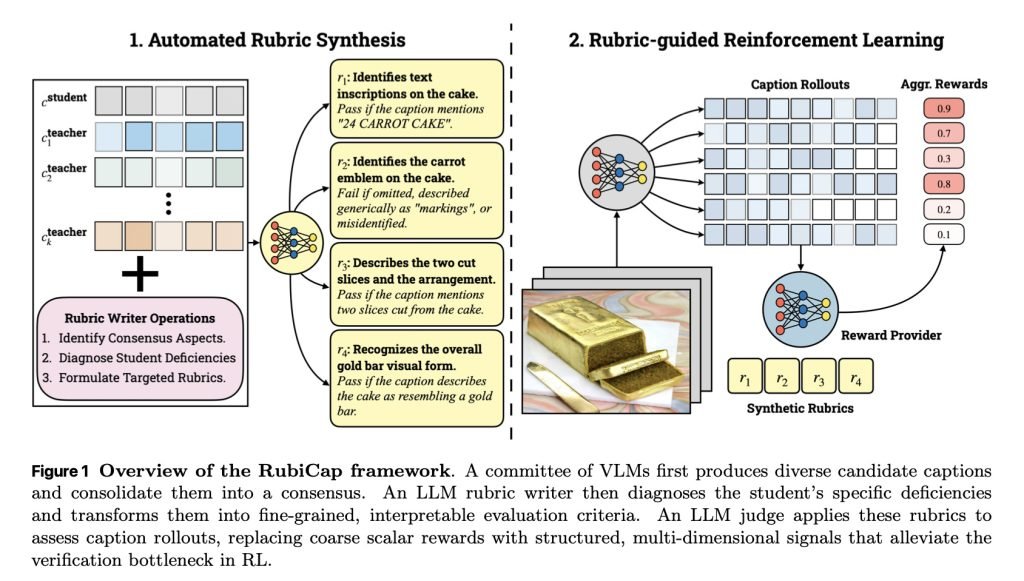
针对这些问题,他们提出了一种新框架,采用了一个挺有意思的办法。
他们从PixMoCap和DenseFusion-4V-100K两个训练数据集里随机抽取了5万张图片。
对每张图片,用一批现有的视觉-语言模型生成多个描述候选,包括Gemini 2.5 Pro、GPT-5、Qwen2.5-VL-72B-Instruct、Gemma-3-27B-IT和Qwen3-VL-30B-A3B-Instruct。
与此同时,正在用RubiCap训练的模型也会自己生成一个描述。
然后,RubiCap让Gemini 2.5 Pro来做下面几件事:
- 同时看图片、候选描述和自家模型的输出;
- 找出大家一致认同的部分,以及哪些地方被忽略或描述错了;
- 把这些整理成清晰的评判标准。
之后,再用Qwen2.5-7B-Instruct作为裁判,根据这些标准给所有描述打分,形成训练所需的奖励信号。
这样一来,模型就能得到更精准、更有结构的反馈,知道哪里需要改进,从而生成更准确的描述,而且不用依赖单一的“标准答案”。
最终,研究团队训练出了三个模型:RubiCap-2B、RubiCap-3B和RubiCap-7B,参数量分别是20亿、30亿和70亿。
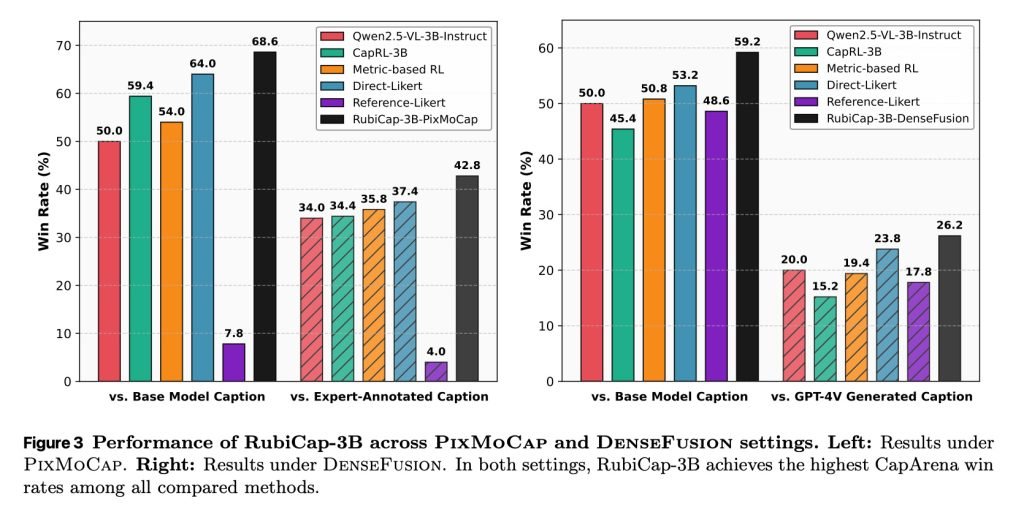
和现有的方法比起来,它们的表现让人意外地好,甚至超过了参数量高达720亿的模型。
研究论文里写道:
在大量基准测试中,RubiCap在CapArena上赢率最高,超过了监督蒸馏、之前的强化学习方法、人类专家标注以及用GPT-4V增强的输出。在CaptionQA测试上,它展示了更好的文字效率:我们的7B模型能达到Qwen2.5-VL-32B-Instruct的水平,而3B模型则超过了对手的7B版本。更值得一提的是,用小巧的RubiCap-3B生成的描述来预训练视觉-语言模型,效果反而比用商用大模型生成的描述更好。
另外:
在盲测排序评估中,RubiCap-7B获得最多第一名的比例,在所有模型里(包括720亿和320亿参数的前沿模型)最高,同时幻觉惩罚最低,准确性最强。
大家可能没注意,研究人员特别提到,参数只有30亿的较小模型,在某些基准上居然超过了它更大的同系列模型。这说明,要做出高质量的密集图像描述,并不一定非得依赖超大规模模型。
下面是RubiCap-7B-DenseFusion和Qwen2.5-VL-7B-Instruct的描述对比示例:




想了解这项研究的更多细节,包括技术术语的深入解释,可以点这个链接查看。