





在 Mac 上本地运行 AI 模型的最好工具之一,现在变得更强了。来看看具体原因,以及怎么用。
Apple 硅基 Mac 上,Ollama 本地 AI 模型现在跑得更快了
如果你还没用过 Ollama,它是一款支持 Mac、Linux 和 Windows 的应用,能让你在自己电脑上直接跑 AI 模型。
和 ChatGPT 这种云端应用不一样——那些模型不跑在本地,还得一直联网——Ollama 可以直接把模型下载到你的机器上运行。
这些模型可以从 Hugging Face 等开源社区下载,或者直接从模型提供方获取,我们之前也介绍过。
不过,在本地跑大语言模型(LLM)其实挺吃力的,哪怕是比较小、轻量的模型,也很容易把内存和显存吃掉不少。
为了改善这个问题,Ollama 刚刚发布了预览版(Ollama 0.19),现在底层换成了苹果的机器学习框架 MLX,利用它统一的内存架构,让 Apple 硅基 Mac 上的本地 AI 模型跑得明显更快。
Ollama 官方是这样说的:
这让 Ollama 在所有 Apple Silicon 设备上的速度都有大幅提升。在苹果 M5、M5 Pro 和 M5 Max 芯片上,Ollama 还能利用新的 GPU Neural Accelerators,进一步加快首 token 生成时间(TTFT)和后续生成速度(每秒 token 数)。
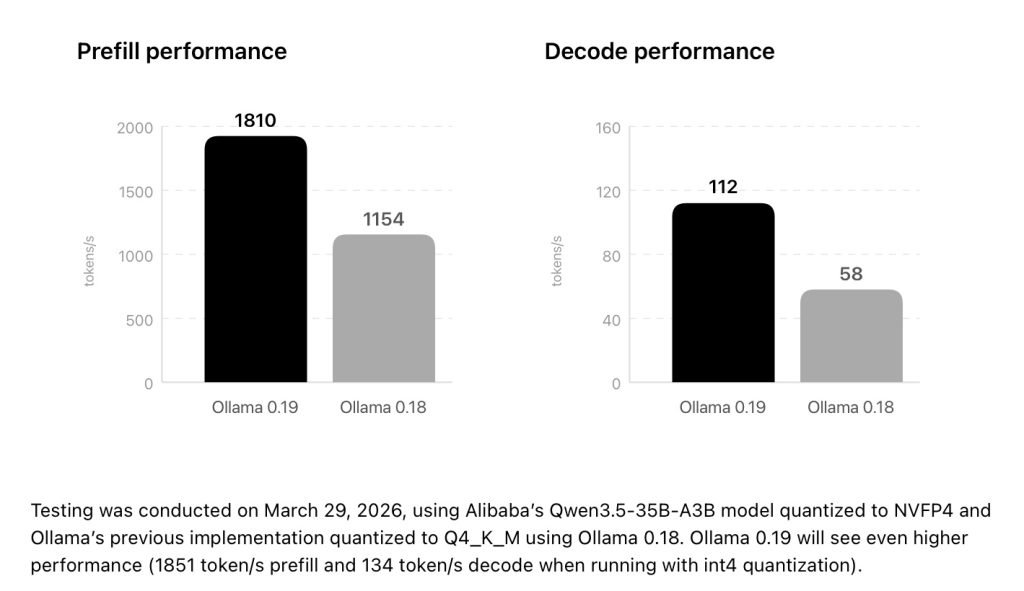
有了这次更新,Ollama 表示现在运行个人助手比如 OpenClaw,以及代码代理工具(如 Claude Code、OpenCode 或 Codex)都会更快。
不过有个小提醒:Ollama 建议用户“最好使用统一内存超过 32GB 的 Mac”,目前很多想本地跑大模型的朋友可能还达不到这个配置。
不管怎样,想深入了解 Ollama 的朋友,可以点这个链接看看。如果你对苹果的 MLX 项目感兴趣,这里有完整介绍。