





在一篇新论文里,苹果的研究团队介绍了一种很有创意的框架,能显著提升大语言模型在数学推理、代码生成等任务上的表现。下面是具体细节。
扩散模型和自回归模型的结合
在一篇最近更新的论文《LaDiR: Latent Diffusion Enhances LLMs for Text Reasoning》中,苹果研究者联合加州大学圣迭戈分校的团队,提出了一种有趣的方法,来改善大语言模型在某些领域生成答案的质量。
以前我们聊过扩散模型,它是通过并行迭代多个token来生成文本的,而自回归模型则是一个接一个地预测下一个token。
苹果之前还研究过把扩散模型用在蛋白质折叠预测和代码生成上,挺有意思的。
简单来说,LaDiR把两种方法结合起来了:在推理阶段采用扩散方式,最后再用自回归方式生成最终输出。
更厉害的是,它能同时运行多条推理路径,每条路径都各自进行扩散过程,还设计了机制让它们探索不同的可能性,从而产生多样化的候选答案。
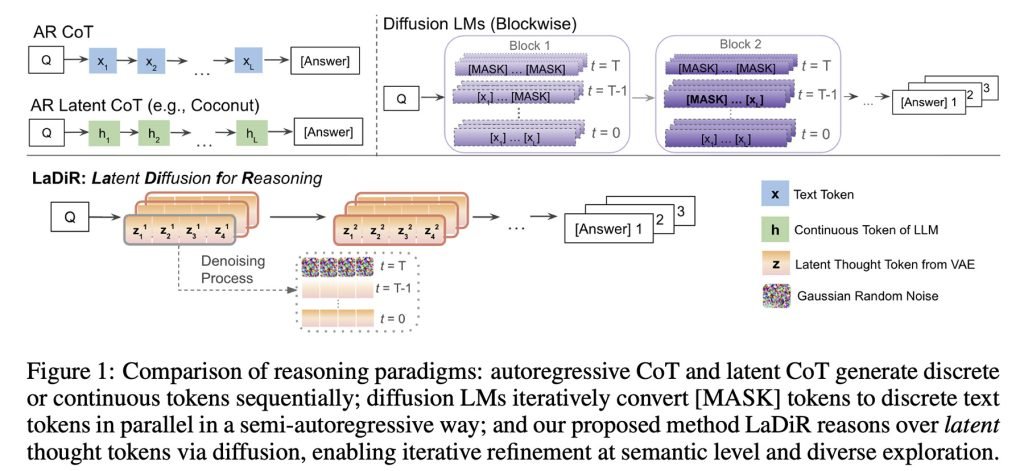
他们解释说,在推理阶段,也就是模型琢磨怎么回答用户问题的时候,LaDiR会先生成一系列隐藏的推理块,每个块一开始都是随机噪声,然后逐步精炼成更连贯的推理步骤。
等到模型觉得推理得差不多了,就切换到自回归模式,一个token一个token地生成最终答案。
关键在于LaDiR能并行处理好几条推理路径,并且有机制防止它们过早收敛到同一个想法上,不然就失去意义了。
值得一提的是,LaDiR本身不是一个全新的模型,而是一个框架,可以叠加在现有的语言模型上。它主要是改变了模型思考问题的方式,而不是彻底替换它们。
LaDiR的表现如何
实验中,研究者把LaDiR用在了Meta的LLaMA 3.1 8B模型上做数学推理和谜题规划,还用Qwen3-8B-Base做代码生成。
在数学基准测试上,LaDiR的准确率比现有方法更高,即使面对更难的、分布外任务也表现得更稳。
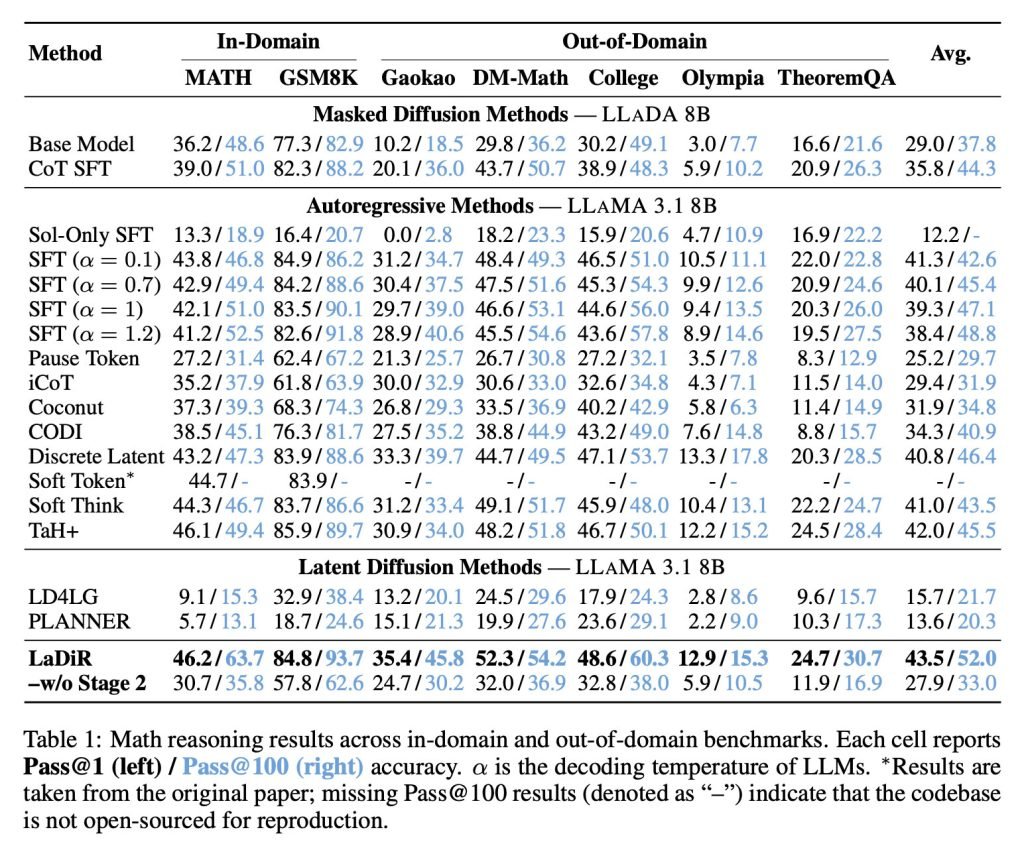
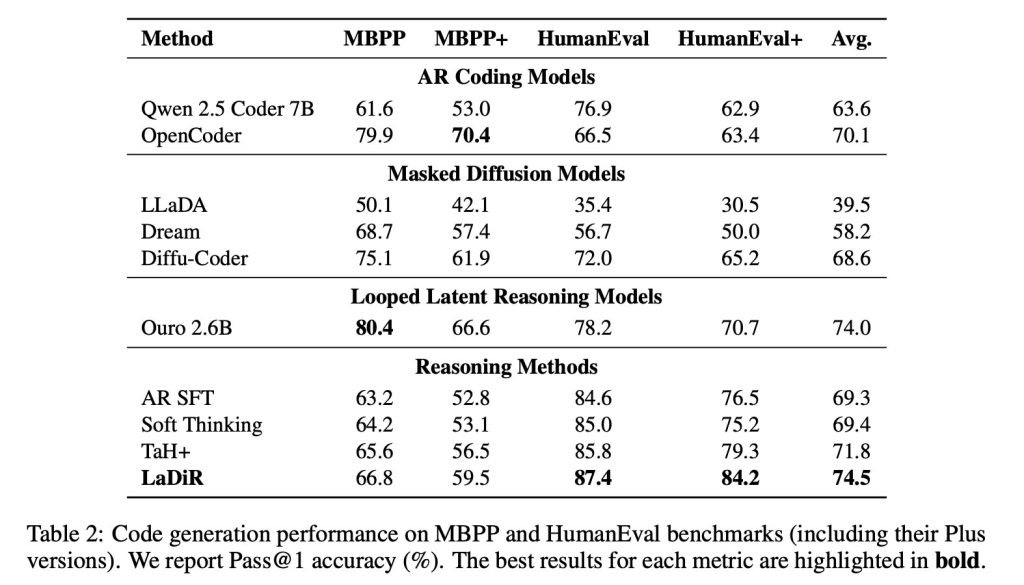
在HumanEval等代码生成基准上,LaDiR输出的结果更可靠,比标准微调方法明显好,尤其在难题上优势更大。
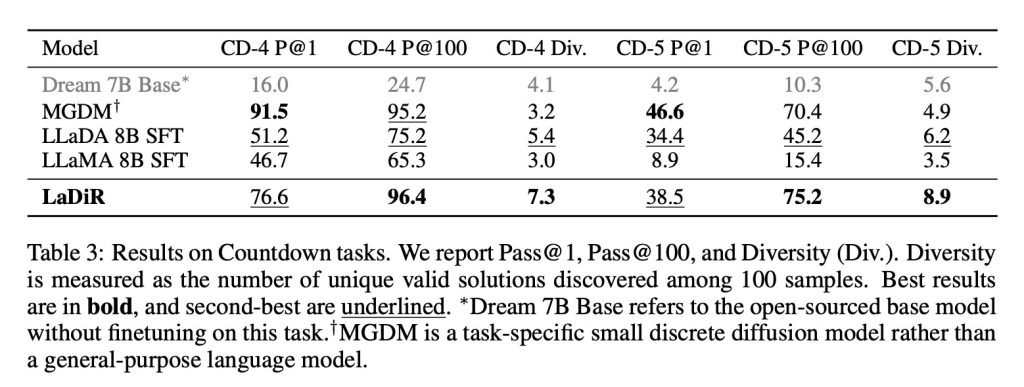
而在像Countdown这样的谜题规划任务中,LaDiR能探索更多有效的答案路径,比所有通用基线模型都更可靠地找到正确解。不过在单次尝试的准确率上,它还是比不过专门针对该任务优化的模型。
虽然LaDiR论文里有些部分挺技术性的,但如果你对大语言模型的内部机制或者提升文本生成性能的新思路感兴趣,这篇还是很值得一读的。
想看完整论文,可以点这个链接。